https://developers.openai.com/api/docs/guides/prompt-guidance
核心提示模式:
- 保持输入内容清晰明了,结构清晰:API中有<output_contract>参数来控制输入的合约。控制模型输出的内容量和输出的结构。
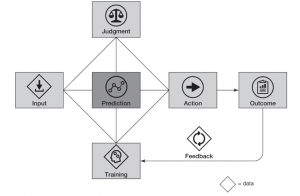
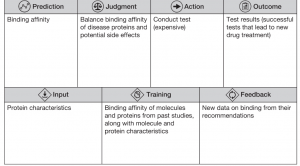
- 为后续行动设定明确的默认值:
- 明确定义何时执行操作、何时询问以及新指令如何覆盖之前的默认设置。
- 指导原则: 当对话过程中指令发生变化时,更新内容应明确、范围清晰且仅限于特定区域。说明哪些内容发生了变化,哪些内容仍然适用,以及该变化是否影响下一轮对话或剩余的对话。
- 处理对话过程中的指令更新:使用明确的、有针对性的引导消息。
- 如果正确性依赖于工具,需要持久使用:
- 输入先决条件、进行依赖关系检查和明确工具的用途。
- 当工作彼此独立且耗时较短时,建议并行执行;当依赖关系、歧义或不可逆操作比速度更重要时,建议顺序执行。
- 长周期任务的完备性:
- 常见的故障模式是执行不完整:模型在部分覆盖后即结束,漏掉批次中的项目,或者将空检索或范围过窄的检索结果视为最终结果
- 明确完成的规则,如果结果返回为空或者不完整,不要立即给出结论,需要做检查
- 在执行高影响操作之前,添加验证循环:
- 在返回答案或者执行不可逆操作之前,添加一个轻量级的验证步骤
- 对于主动采取行动的代理,添加一个较短的执行验证流程
特定工作流程:
- 视觉应用需要明确图片的细节参数:<detail>: low high original auto
- 对引用有要求,需要明确范围和格式:使用内联引用或者脚注,保持一致性
- 研究模式:用于研究、评论和综合任务
- 严格限制输出格式:
- SQL、Json,需要告知模型输出,并在完成之前进行检查
- 提取文档或者OCR,需要定义坐标系并添加漂移检查
- 编码和终端工具中,需要明确使用边界
- 编码任务:
- 高风险变更需要一个轻量的验证机制
- 在关键节点需要进行状态持续更新
- 格式化:可能过度使用结构化形式。如果需要简洁需要限制
- 前端任务:需要额外的前端任务指导,可以使用<frontend_tasks>
- 长时间运行和工具繁重的任务,运行状态需要维持,使用phase参数、previous_response_id
- 压缩技术可以显著延长有效上下文窗口:<Compaction>。在主要里程碑事件后进行压缩,压缩后的内容视为不透明状态,确保压缩后提示的功能完全相同
- 用户工作流的个性化:持久个性化和每次控制分离
- <Personality>(持续):决定整个会话的默认基调、语速和决策风格
- <Writing controls>(每轮对话回复):定义特定对话的渠道、风格、格式和长度
- 提醒:任务特定的输出要求会覆盖Personality
- 写出自然流畅高质量的有效控制手段:清晰的人物形象、指明渠道和表达风格、写散文则不限制格式、使用严格的长度限制
- 专业备忘录格式:用于备忘录、评论、专业写作。memo_mode。
- 需要明确的指导,包括措辞的精确性、领域惯例、综合分析以及恰当的表达方式。
- 对于法律、政策、研究和面向高管的写作尤其有用,包含严谨的推理和清晰的结论。
推理程度:
- 推理程度是最后的微调手段,不是提升质量的主要途径
- none:速度快、成本敏感、对延迟敏感的任务,不需要思考
- low:少量思考可以显著提升准确率
- medium / high:用于真正需要更强推理能力且能够承受延迟和成本权衡的任务
- xhigh:适合耗时较长、需要大量自主决策和推理的任务。智能优先级高于成本和速度
- 在增加推理程度前,先尝试<completeness_contract>、<verification_loop>、
<tool_persistence_rules>
其他模型:
- gpt-5.4-mini:假设更少、适合任务结构清晰。默认会尝试通过后续问题来继续对话
- 关键规则放在首位
- 使用工具需要指定执行顺序
- 不只是依赖“You Must”,使用结构化的辅助工具,例如编号的步骤、决策规则和明确的行动定义
- 将“执行操作”与“报告操作”分开
- 展示正确的流程,而不仅仅是最终格式
- 明确定义歧义行为:何时询问、何时回避、何时继续
- 直接指定包装:答案长度、是否提出后续问题、引用格式和章节顺序
- 注意不要使用 output nothing else 。最好使用作用域明确的指令,例如 after the final JSON, output nothing further
- gpt-5.4-nano:范围狭窄、界限明确的任务。优先选择封闭式输出:标签、枚举、简短的 JSON 或固定模板。
- 默认模式:task、Critical rule、Exact step order、Edge cases or clarification behavior、Output format、One correct example
- 避免:隐含的后续步骤、未指定的极端情况、仅包含架构的工作流、无结构的通用指令
Best practices for prompt engineering with the OpenAI API
- 使用最新最强的模型。
- 将提示和需要处理的目标对象分离:可以使用###或者是””””来明确目标对象。
- 请尽可能具体、详细地描述所需的内容,包括预期结果、长度、格式、风格等等。
- 通过示例阐明所需的输出格式。
- 先尝试零样本,然后尝试少样本,都不成功,最后进行微调。
- 减少“空泛”和不精确的描述
- 别说不要做什么,说应该做什么。
- 代码生成专用 – 使用“引导词”来引导模型朝着特定模式发展
- 例如python使用“import”,sql使用“select”
- 使用“生成任何内容”功能
- 需要适配的参数:模型、temperature、max_completion_tokens、stop
- temperature:越高越不稳定和有创意,要求事实性的场景使用0更稳定
- stop:如果生成了相关内容,就直接停止生成
OpenAI最新的模型:https://developers.openai.com/api/docs/models
https://developers.openai.com/cookbook/examples/gpt-5/prompt_personalities